
Recently I’ve been involved in drupal.org by upgrading the site to the latest version of Apache Solr Search Integration (from 6.x-1.x to 6.x-3.x, and in the near future to 7.x-1.x). This upgrade path is necessary as we still want to have a unified search capability across Drupal 6 and Drupal 7 sites, for example groups.drupal.org and drupal.org.
If you want to know more about multisite search capabilities with Solr and Drupal, I suggest you read http://nickveenhof.be/blog/lets-talk-apache-solr-multisite as it explains a whole lot about this subject.
One issue that we encountered during the migration is that all content needed to be reindexed, which takes a really long time because Drupal.org has so much content. The switch needed to happen as quickly as possible, and the out-of-the-box indexer prevented us from doing this. There are multiple solutions to the dev/staging/production scenario for Solr, and I promise I will tackle those in another blogpost. Update: I just did http://nickveenhof.be/blog/content-staging-apache-solr
This blogpost is aiming on making the indexing speed way quicker by utilizing all the horsepower you have in your server.
Problem
Take a look at the normal indexing scheme :

This poses a number of problems that many of you have encountered. The indexing process is slow not because of Solr, but because Drupal has to process each node one at a time in preparation for indexing. And a node_load/view/render takes time. And what about Solr? Solr does not even sweat handling the received content ;-)
function apachesolr_index_node_solr_document(ApacheSolrDocument $document, $node, $entity_type, $env_id) {
...
// Heavy part starts here
$build = node_view($node, 'search_index');
unset($build['#theme']);
$text = drupal_render($build);
// heavy part stops here
...
You could avoid this by commenting this code out and not have the full body text, which is useful if you only want facets. It could also be optimized by completely disabling caching since we do not want these nodes to be cached during a massive indexing loop. You can view the Cache disable blogpost figure out how I’ve done that.
Architecting a solution
And this is the parallel indexing scheme :
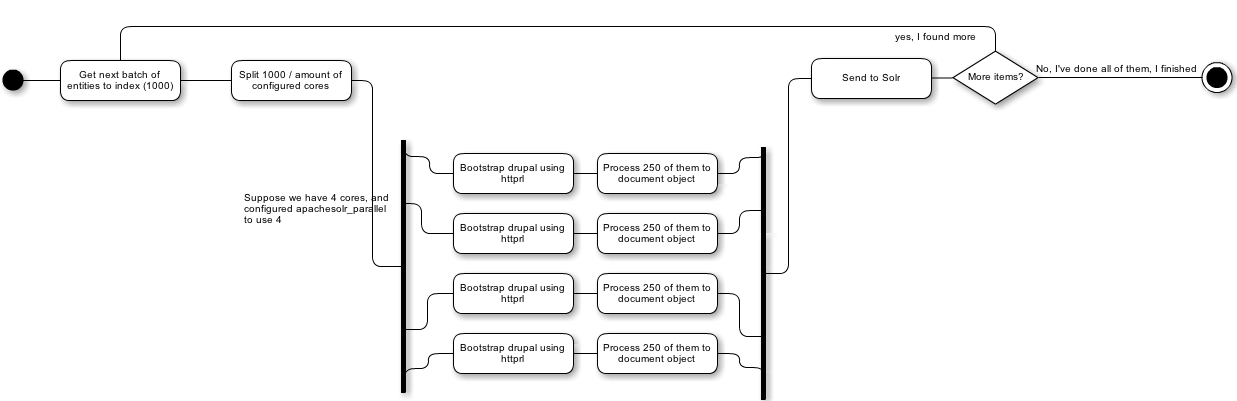
I went looking for a solution that could provide an API to achieve this architecture. After learning a lot about the php fork method it seemed way too complex for what I would need. Httprl on the other hand looked like a good solution. With an API that allowed me to execute code on another bootstrapped drupal and by making this a blocking request, but in parallel, I could execute the same function multiple times with different arguments.
What does httprl do? Using stream_select() it will send http requests out in parallel. These requests can be made in a blocking or non-blocking way. Blocking will wait for the http response; Non-Blocking will close the connection not waiting for the response back. The API for httprl is similar to the Drupal 7 version of drupal_http_request().
As a result, I created the Apache Solr Parallel Indexing module which you can download, enable, configure the achieve parallel indexing.
Try it out for yourselves
- Enable Module
- Go to admin/settings/apachesolr/settings
- Click Advanced Settings
- Set the amount of nodes you want to index (I’d set it to 1000)
- Set the amount of CPU’s you have (I’ve set to 8, I have 4 physical, but they can handle 2 indexing processes each)
- Make sure you have the hostname set if your IP does not directly translates to your domain
- If your IP does not resolve to your drupal site, go to admin/settings/httprl and set it to -1. This will almost always be the case for testing
- Index
- using the batch button in the UI
- Using drush : drush –uri=”http://mydrupal.dev” solr-index
As you can see, the drush command stays the same. The module will take over the batch logic, so regardless of the UI or drush, it will use multiple drupal bootstraps to process the items.
Results
Hardware : Macbook Pro mid 2011, i5, 4GB RAM, 256GB SSD
I’ve seen a 4x-6x improvement in time depending on the amount of complexity you have in node_load/entity_load.
Without Parallel Indexing
- Calculation : 40k nodes in 20 minutes
- Nodes per second : 33
With Parallel indexing
- Calculation : 117k nodes in 19 minutes
- Nodes per second : 112
Another example I got from swentel is this :
Without Parallel Indexing
- Calculation : 644k nodes in 270 minutes
- Nodes per second : 39
With Parallel indexing
- Calculation : 664k nodes in 90 minutes
- Nodes per second : 119
Calculating this in to a million nodes, it will take on average 3 hours to finish the whole lot. Comparing this with a blogpost that talked about speeding up indexing and clocked at 24 hour per million, this is a massive improvement.
In the real life case of swentel, this has had an impact of factor of 3. Meaning the indexing went 300% faster compared to not using the module. I’d say its worth to look at it at least.
Take a look at the screenshots below how I measured and monitored all of this, it was fun!
Future & Improvements
It is still an exercise of balance, the bigger your Drupal site, the longer it takes. As the drupal.org team has this in production, they encountered some problems of overloading their systems. If you overload the system, it is possible that the timeout of the request has crossed its limit and will die. This means that you won’t get feedback on how many items it has processed. As a general rule, do not set the amount of cpu’s too high. Perhaps half of what you really have to start with and experiment. Be conservative with these settings and monitor your system.
I also would like to experiment with the drupal queue, but this is a D7 only API and as this module had to work with Drupal 6 and 7, I decided to opt for this simpler approach. There is a great blogpost about Search API and Queue’s but it involves some coding.
