You don't *just* install a new version!
I'm sure you had this situation before : "A new version arrives, they promise you heaven and when you take the dive you actually are in hell. Everything is broken and you don't really understand why". A very common case of diving in to the deep. To prevent this I was asked, during my internship at Acquia, to verify if the new Solr 3.5 would perform at least equally well at the exact same searches as it did with Solr 1.4. Before upgrading a lot of testing should happen so that nobody is surprised with sudden problems.
During this process I learned a bunch about Solr server administration, master/slave replication and load testing. Hopefully I've saved you some time in your exploration of the solrconfig and its mergePolicies! And moreover I'd like to thank Acquia and especially Peter Wolanin for his guidance!
What we do know is that the index format of Solr 1.4 can be read by Solr 3.x. This is crucial information to have when updating existing indexes. Be warned, there is a very important difference to be made when updating masters and slaves in a replication setup. When upgrading, you should always upgrade your slave first! If you upgrade your master first, and a 3.5 index is being replicated to a 1.4 Slave, you are asking for troubles.
A soon as a first commit/write action is made, Solr will execute an index upgrade process. A fresh index or a re-index is recommended, but it will certainly still work
This blog post was published some time ago, but I am re-publishing this since we have finished the migration of Acquia Search to Solr 3.5 with success so hopefully this will be of interest for some of you.
Drupal is an application that has very deep integration with the Apache Solr application and is updating Solr during cron runs (every 30 minutes for example). This does imply that the indexing speed should not be very high but the search speed should be. Apache Solr has a concept of segments (your index is spread over multiple segments) and if a search is executed it needs to gather all these segments and search them. Logically, more segments = slower results.
Solr 3.5 came with a new default MergePolicy and that required some testing to see if we could trust this new MergePolicy (TieredMergePolicy).
Information regarding these policies can be found here : http://java.dzone.com/news/merge-policy-internals-solr
And read up on the following docs :
Steps taken to execute these tests
- Load existing index files in to a new core.
- Extract Documents from this index
- Use the extracted documents to insert them in a clean and new core with different configuration
- Re-run the access log of that subscription for the searches, repeat this twice, use 3000 queries per access log and discard everything except the select queries and repeat this process 3 times to make sure we have a balanced result set
- If you have more questions about these tests, please leave a comment and I'll be happy to provide you with an answer!
Conclusions
If you want to migrate to Solr 3.5 coming from Solr 1.4 with low risk of changes you should keep using the LogByteMergePolicy with a mergefactor of 4 (Default in the Drupal configs). However, the TieredMergePolicy is interesting when understood correctly. I'd love some more comments on that topic from people that know more about it.
The big result of this test is that Solr 3.5 versus 1.4 is a big big performance win. Also good to know is that the MergePolicy should be set explicitly when using LuceneMatchVersion.
Carefully I dare to say that the difference between RHEL5 and Ubuntu 10.04 are immense. I have to do some extra testing to be sure that this result is actually true
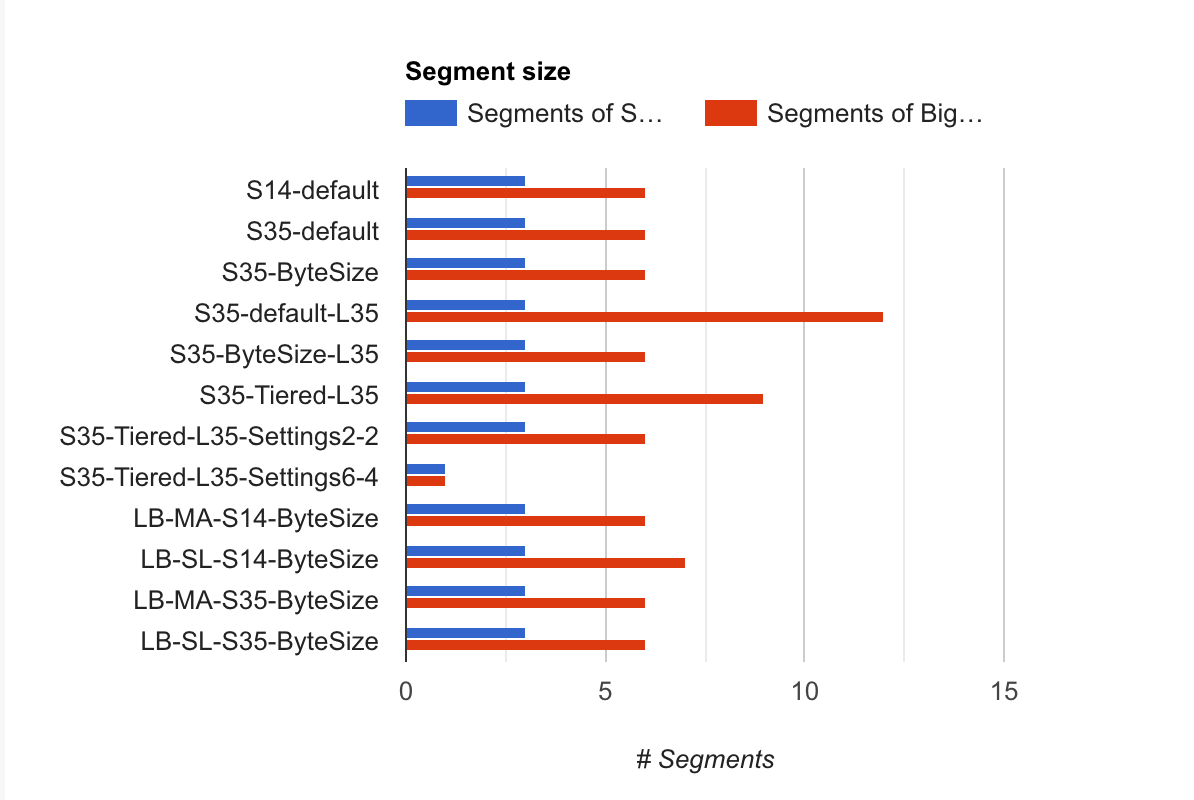
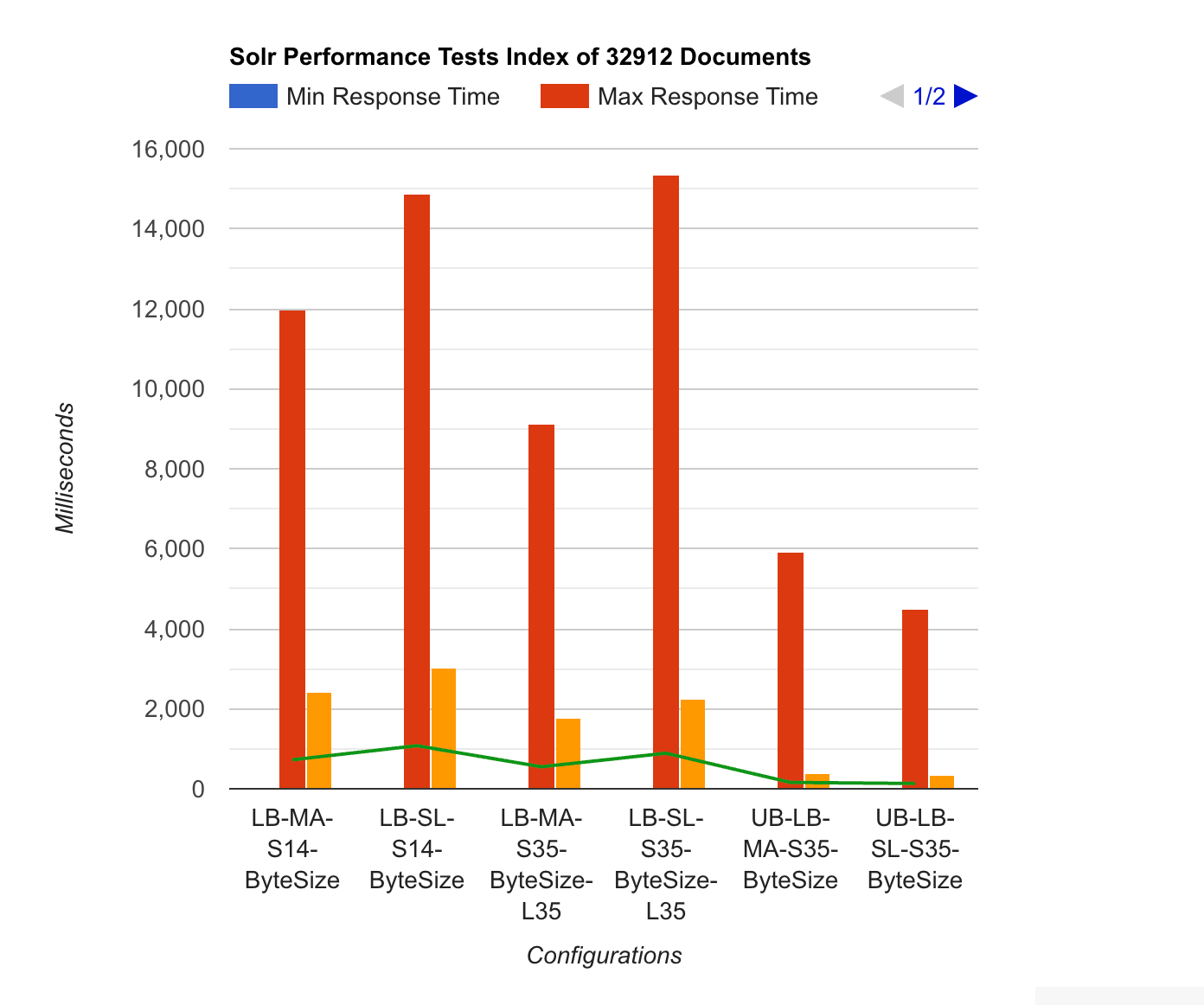
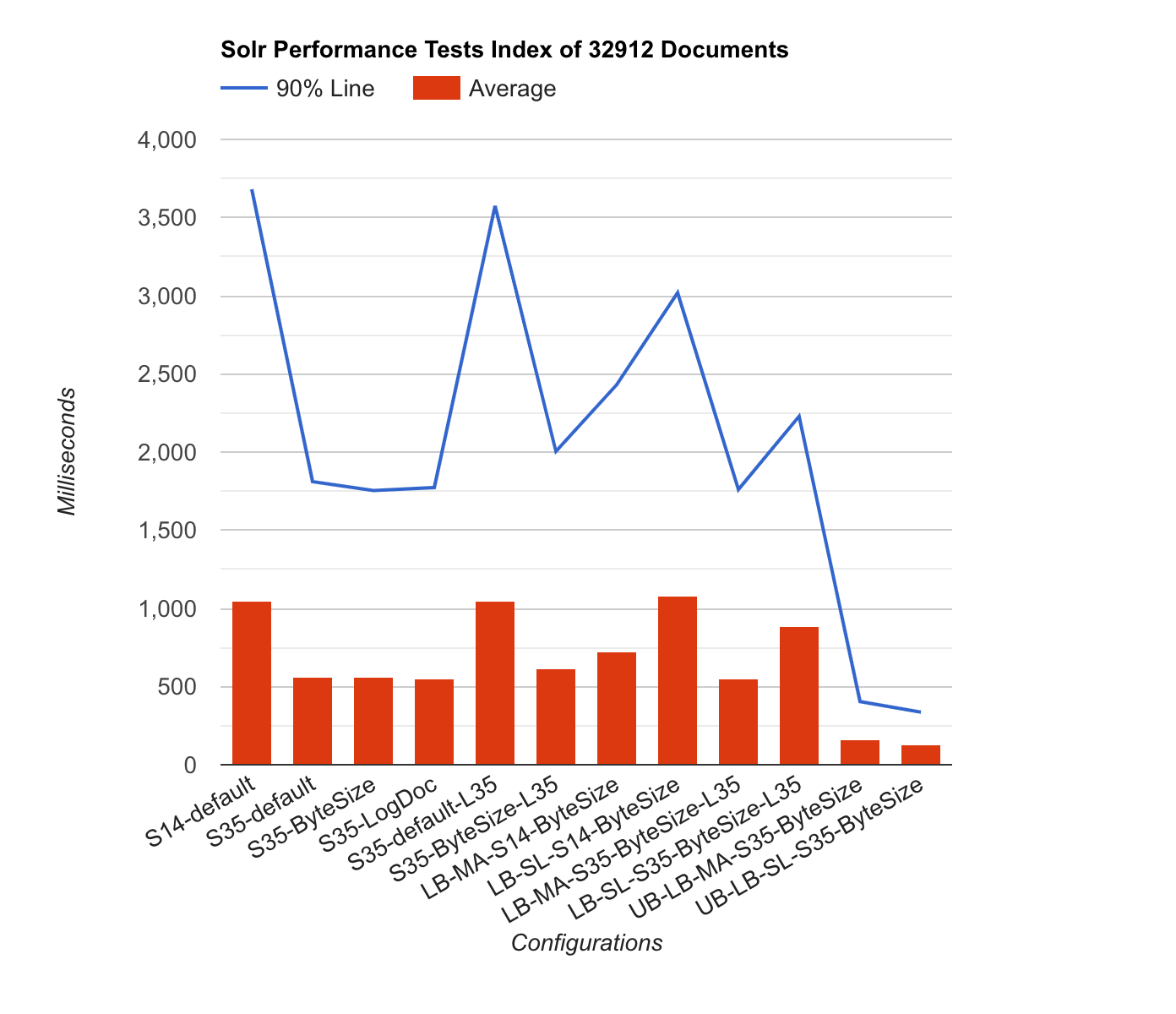
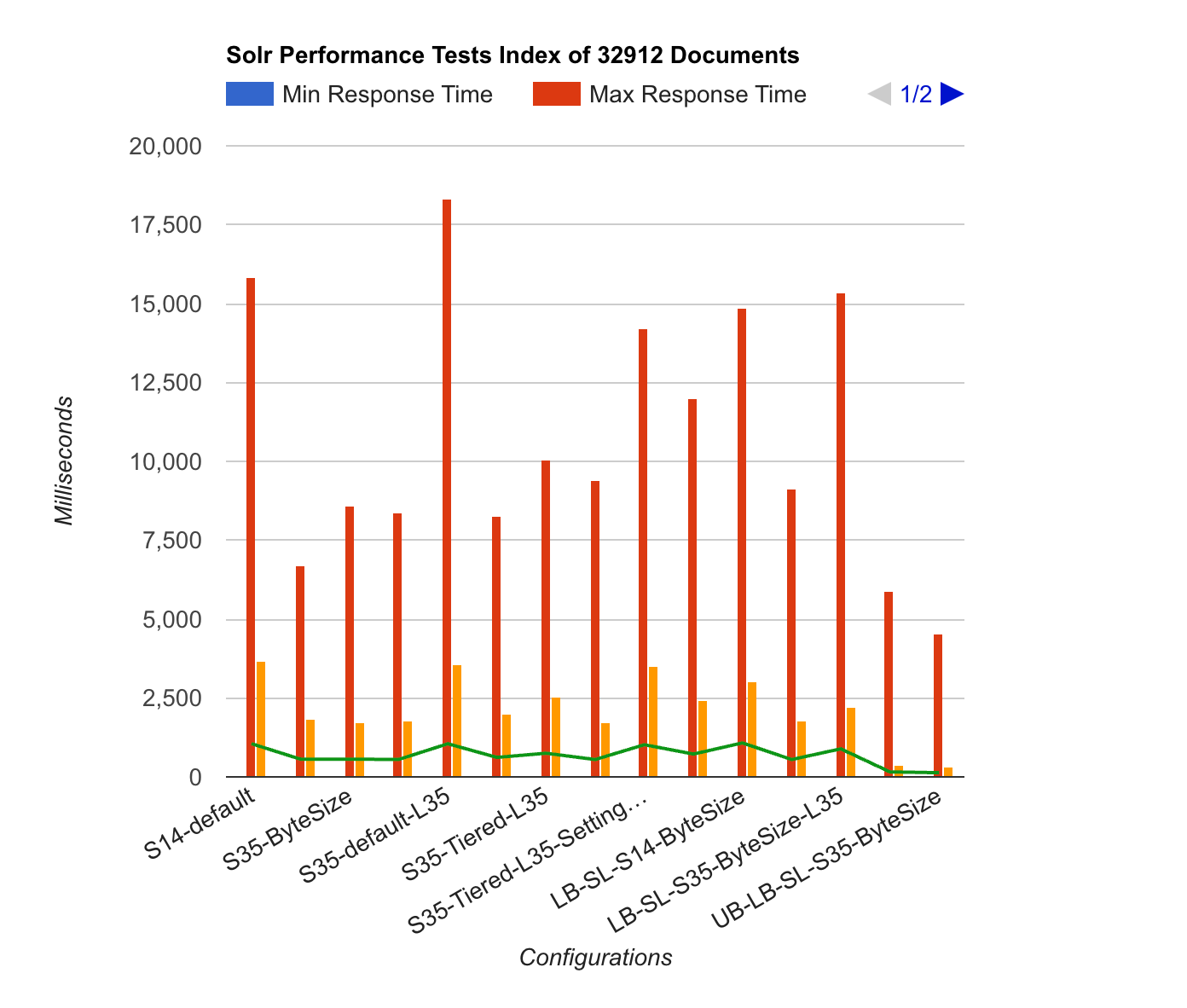
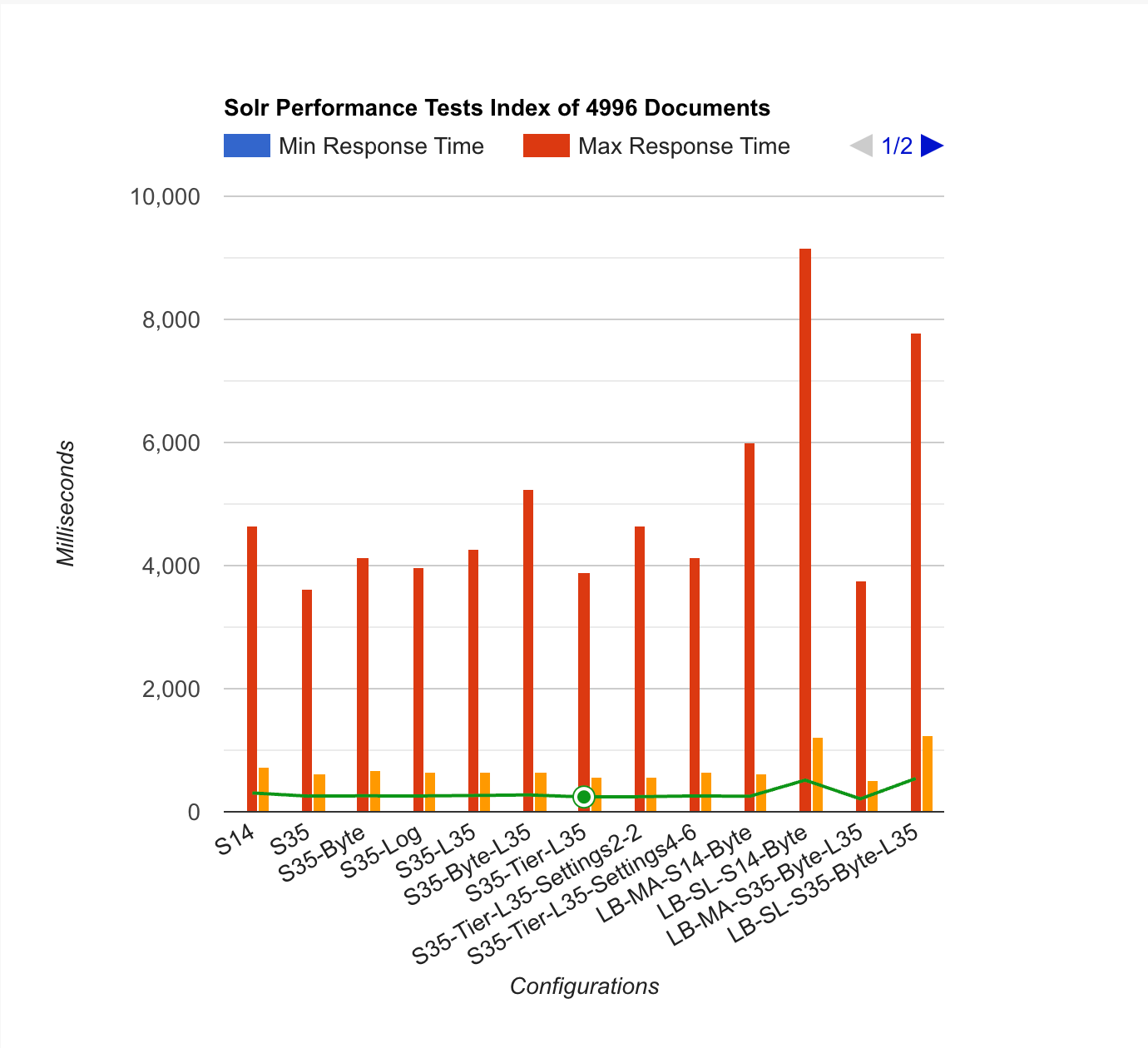
Charts and extra Legend information
- S14 stands for Solr 1.4
- S35 stands for Solr 3.5
- LB stands for Load Balancer (C1.medium)
- SL stands for Slave, this means that the attack happened from the LB to the SL (these results happend 3 times for to contain less variable delays)
- MA stands for Master, this means that the attack happened from the LB to the MA (these results happend 3 times for to contain less variable delays)
- MergeFactor for LogbyteMerge and LogDocMerge is set to 4
- Default means the Default merge policy, Solr 1.4 this is LogByteMergePolicy and for Solr 3.5 this depends on the LuceneMatchVersion
- L35 means that Lucene has been set to Lucene 3.5 instead of the default
- When Lucene 3.5 is set for Solr 3.5 and no merge policy was set, this defaults to TieredMergePolicy
- When Settings is defined, it applies to specific TieredMergePolicy settings
- maxMergeAtOnce says how many segments can be merged at a time for "normal" (not optimize) merging
- segmentsPerTier controls how many segments you can tolerate in the index (bigger number means more segments)
- Distro /Kernel version for most of them CentOS 5 2 32 2 6 18 200906190310 / 2.6.18-xenU-ec2-v1.0
- U stands for Ubuntu : Ubuntu 10.04.4 LTS / 2.6.32-341-ec2
Specifications
Specifications of the Master
Large Instance (M1.large) 7.5 GB memory 4 EC2 Compute Units (2 virtual cores with 2 EC2 Compute Units each)
Specifications of the Slave
High-CPU Medium Instance (C1.medium) 1.7 GB of memory 5 EC2 Compute Units (2 virtual cores with 2.5 EC2 Compute Units each)
