in the second part of this Let’s talk Apache Solr I’ll be handling the revamp of Apache Solr Attachments. Apache Solr Attachments is a module that allows you to index documents. File formats that can be indexed include HTML, XML, Microsoft Office documents, OpenDocument, PDF, RTF, .zip and other compression formats, text formats, audio formats, video formats and more. For a complete list of supported document formats, see the Apache Tika documentation.
This module is great when you have a content-rich website where the search should extend to anything further than regular site-content search. The module already exists since the early days of Drupal 6, where there was not even a discussion about entities. We were talking about nodes as if they were the only important thing that would ever exist in Drupal. Anything could be done with nodes, you name it! And I’ll tell you… I’ve seen some ugly things that people have done with those poor nodes…
As we progressed in to the Drupal 7 era, it became clear that entities are now to be treated with respect and therefore code had to be refactored.
Architecture
In order to understand the major improvements, take a look at the following diagram.
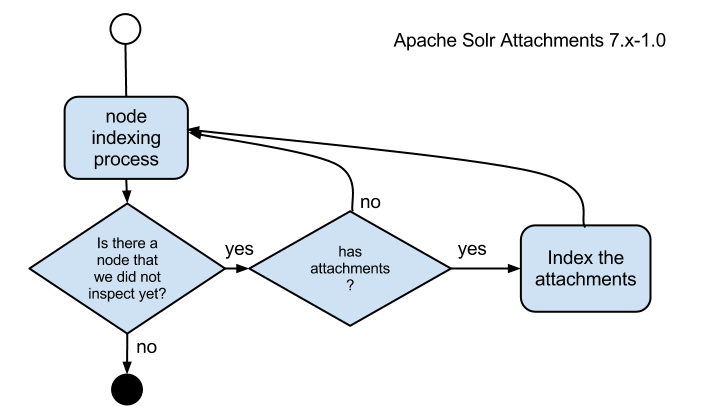
So, in earlier versions, it inspected every node to see if it had an attachment. However, this had 1 big flaw. Suppose you have a million nodes, and only 10 nodes had files attached to them, it still had to inspect those million nodes. Naturally this results in a slower system where a bunch of cpu cycles are not really being used for useful computing. Because of the Drupal 6 architecture it was the only way to get a reliable graph of the attached files.
Now, let’s take a look at the newer version.
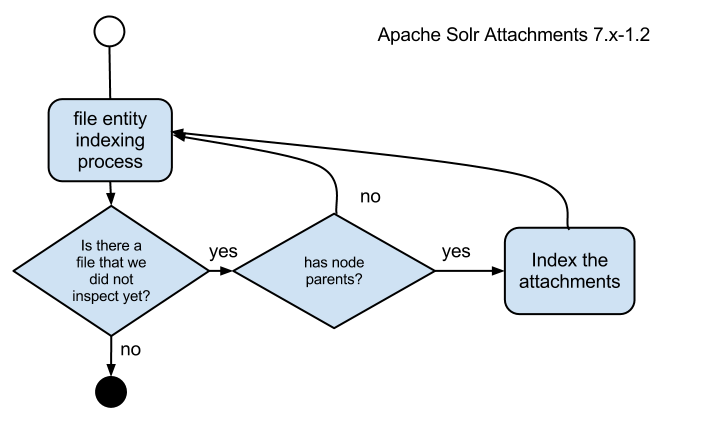
It makes use of the EntityFieldQuery to fetch the files that are attached to entities (most probably nodes, see limitations). Let’s look at the following snippet that fetches all files from filefields in entities that have the filefields defined. This is a little bit stripped down, so I hope it is still readable. You will notice that we spawn an object called ApachesolrAttachmentsEntityFieldQuery. This is due to the fact that a regular EntityFieldQuery can’t return anything else aside from entity_id, entity_bundle and entity_type. We needed the file id from the filefield for those entities without creating complex code, so we embraced the OO concepts and extended EntityFieldQuery.
// Get all the fields in our system
$fields = field_info_field_by_ids();
foreach ($fields as $field_id => $field_info) {
// if the field is typed as file, continue
if ($field_info['type'] == 'file') {
// find the entities and bundles where this field has been attached to
foreach ($field_info['bundles'] as $entity_type => $bundles) {
$entity_info = entity_get_info($entity_type);
$query = new ApachesolrAttachmentsEntityFieldQuery();
$results_query = $query
->entityCondition('entity_type', $entity_type)
->fieldCondition($field_info['field_name'])
// Fetch all file ids related to the entities
->addExtraField($field_info['field_name'], 'fid', 'fid')
->execute();
$results = array_merge_recursive($results, $results_query);
}
}
}
return $results;
If you want to see how it works, or you want to use this in your own project you can take a look at the sandbox pcambra and I created Entity Field Query Extra Fields. The addExtraField() function was added in our extended class and basically allows you to ask for any value of a row that is available in the data storage for your field.
What we achieved here is a stable and reliable way to get all attached files without inspecting each and every node separately. Definitely a huge #win!
Media
Another interesting improvement is that Apache Solr Attachments now has Media/File Entity support. Media is a drop-in replacement for the Drupal core upload field with a unified User Interface where editors and administrators can upload, manage, and reuse files and multimedia assets. Any files uploaded before Media was enabled will automatically take advantage of for many of the features it comes with.
One of the challenges here was that Media/File Entity added multiple bundles to the file entity type and that the fields are more dynamic. I’m sure not all use cases have been tested but so far you can already select any of the media entity bundles and let them index. As far as I, and many others in the queue, have tested this works quite well.
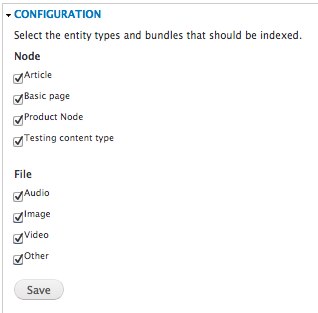
Different indexing methods
Just to point out, because this is not new. Apache Solr Attachments can extract info from a separate tika jar file, hosted on your website or from an embedded tika app in Apache Solr. This is an advantage because, when set up right, you can offload this processing to solr. Preferably this is a redundant solution so it can handle the heavy lifting for you. Acquia Search allows you to seamlessly integrate this module in your website because it offers the ability to extract attachments for no additional fees. Take care when you set this up yourselves so that your search queries are not slower during the extracting of document content.
Limitations
Please note, files that are not attached to another entity won’t be indexed by default. It is certainly possible, but nobody has asked for it yet. Also, even though the code supports files that are attached to anything else than nodes, it has not been tested yet. Do you know a use case for this and are you able to test it? Please go ahead and report back in the issue queue of Apache Solr attachments.
If this interests you, we welcome you to help us making Apache Solr Attachments better! Questions and or remarks are very welcome.
