The problem
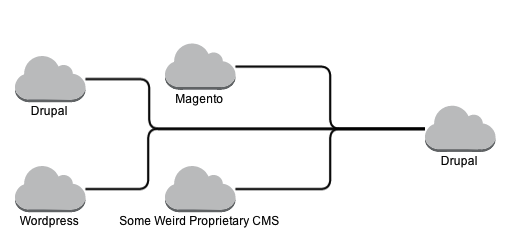
Search is a hard problem, it really is. Let me show this by using an example of a food chain that wants to add Drupal as their homepage of the whole chain. Of course, like many other organisations they do not only have Drupal running but also a subset of other web frameworks open and closed source systems.
Now, they wanted Drupal to become the front-page of all that content, but would you want to migrate all of this content in Drupal just so it becomes navigable so the Drupal site could redirect all content to the right site? Since we do not want our Drupal site, that will become our front page/portal of all this content, to directly reach out to all these other systems, because that would be impossible to scale and maintain, we are thinking of using Apache Solr as our Search Index to serve all this different content to our system.
A possible solution
One of the possible solutions is to convert all non-Drupal sites to Drupal sites and use the Apache Solr Multisitesearch module. By indexing all your content from all Drupal sites into the same Apache Solr index will allow you to search across all of them simply by using 1 query to the Apache Solr index. Since we know we are using Drupal and the module version is the same we know that we are capable of searching all this content in a similar way. We call this the Drupal way, since all knowledge on how the mapping between the Drupal fields and the Solr index is inside the Drupal module and is a “Drupalism”.
What if we want to add content from non-Drupal sites?
That’s a very good question, as a organisation that maintains multiple websites with different technologies you are not always able to switch all of them to the same platform or keep everything updated in a similar fashion.
Luckily the Apache Solr already did the groundwork to make this possible. The way the Apache Solr Search module works is that it is completely independent from the Drupal nodes on the website it is running. It will show you whatever is in the Apache Solr index as long as it follows some very basic structure :
- id
- site
- content
The Apache Solr Search module does not need much more than this information to just show data from other sources. But we now encounter another problem. We do want to see more contextual information than just a title and a snippet. We want to use all possible data and we can describe that as a mapping problem because the module translates field names to solr field names and this could wildly differ from site to site. Even if you only use Drupal sites!
Note: not all these fields are mapped in the same as they would be mapped for real, I invented a quick mapping but the concept should be clear. The solr fields that are used in the index are shown in Bold
An Example
Site 1
- Content type : Event
- Field : field_startdate -> dm_field_startdate
- field : field_enddate -> dm_field_enddate
- field : field_location -> ss_field_location
- field : field_description -> ts_field_description
Site 2
- Content type : Event
- Field : field_start -> dm_field_start
- field : field_end -> dm_field_end
- field : field_location_event -> ss_field_location_event
- field : field_body -> ts_field_body
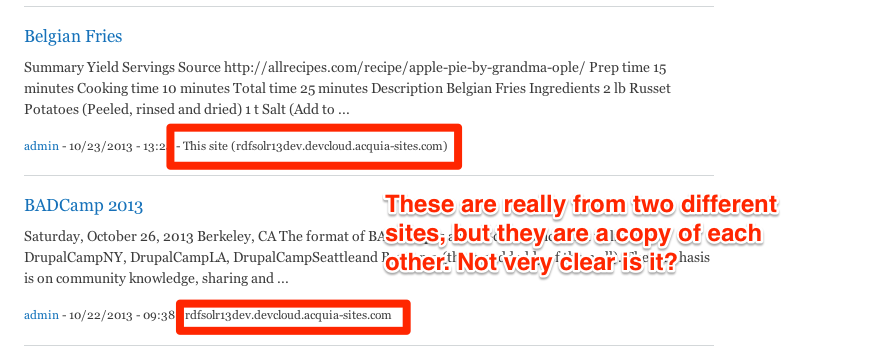
Both sites have Drupal of a same version and have the same module version of Apache Solr Search installed, yet they are not able to share this information across systems as we lack a way of understanding what each field is. We are essentially missing the semantic data that describes this field in a generic way.
To make it even more complex I’ll add third site with Events that is non-Drupal, say it’s Wordpress and we prefix everything with WP because of some decision in the system. I do not claim that WP does any of this, it’s for the sake of the argument ;-)
Site 3
- Content Structure : Event
- Field : wp_startdate -> dm_wp_startdate
- field : wp_enddate -> dm_wp_enddate
- field : wp_location_event -> ss_wp_location_event
- field : wp_descripton -> ts_wp_description
Even if we have a way to index this content in Solr via Wordpress, we do not have a shared agreement on how to name these Solr fields and so we miss out on tons of features such as sharing Facets to filter all of our content in a consistent way and we are not able to show consistent Rich Snippets.
Rich snippets are a way to show metadata in search results. Google has more info about them
Another possible solution using Semantic Data
Describe all of our structured content with Semantic Data such as schema.org and RDFa so that we can translate this in common field names and in effect translate this in common solr field names! By using the CURIE standard and the rdfx module (that requires the ARC2 library) that can translate CURIE uri’s to full uri’s we can now easily have a common way of figuring out how our fields should be named.
Site 1
- Content type : Event
- Field : field_startdate -> schema:startDate -> http://schema.org/startDate -> dm_httpschemaorgstartdate
- Field : field_enddate -> schema:endDate -> http://schema.org/endDate -> dm_httpschemaorgenddate
- Field : field_location -> schema:location -> http://schema.org/location -> ss_httpschemaorglocation
- Field : field_description -> schema:description -> http://schema.org/description -> ts_httpschemaorgeventdescription
Site 2
- Content type : Event
- Field : field_start-> schema:startDate -> http://schema.org/startDate -> dm_httpschemaorgstartdate
- Field : field_end -> schema:endDate -> http://schema.org/endDate -> dm_httpschemaorgenddate
- Field : field_location_event -> schema:location -> http://schema.org/location -> ss_httpschemaorglocation
- Field : field_body -> schema:description -> http://schema.org/description -> ts_httpschemaorgdescription
Site 3
- Content Structure : Event
- Field : wp_startdate-> schema:startDate -> http://schema.org/startDate -> dm_httpschemaorgstartdate
- Field : wp_enddate -> schema:endDate -> http://schema.org/endDate -> dm_httpschemaorgenddate
- Field : wp_location_event -> schema:location -> http://schema.org/location -> ss_httpschemaorglocation
- Field : wp_description -> schema:description -> http://schema.org/eventDescription -> ts_httpschemaorgdescription
Note: We include the schema.org url as we can have different sources for RDF metadata and these can mean different things.
By defining our structure in a standard way we now have uniformity in our Solr index field mappings and can do really cool things with this

What can you do already?
All of this is already possible if you install the rich_snippets module and use branch 1815744, I committed the test code to index and register facets based on these RDF mappings. An example site can be seen here : http://rdfsolr13test.devcloud.acquia-sites.com
Future possibilities
By having a crawler that implement this exact same mapping schema we can show external content from sites we don’t maintain in our Drupal site. By imitating a content type in Drupal and define the mappings for those fields we are able to “identify” similar content and show those in the search index. This opens a lot of possibilities of bridging the gap between Drupal and non-Drupal sites without requiring a massive migration. It also places Drupal in a position that is suited for rapid development as content can quickly be brought available through the means of a shared Solr index.
There is still some work to make it easier, but I think we are already half way by defining what we want and by defining a standard on how we map rdf properties to solr field names and I’ve been thinking to make a very easy library for this so it can be common good and escape the Drupal island.
Thoughts? Ideas? Excited? Please leave a comment :-)
